














Generative AI is quickly being adopted by companies in every sector—from healthcare and the public sector to retail, manufacturing, banking, and financial services. This rapid adoption is understandable. GenAI can assist employees with routine tasks and assist with workplace automation, boost productivity, and provide personalization features to websites and online tools. These capabilities are exciting and have captured the imagination and interest of Wallstreet and the world.
However, GenAI is a tool that can be used for positive and negative purposes. I’ll let other people focus on telling you the positive capabilities of GenAI. As a cybersecurity leader, my job is to remind you of the Generative AI risks so that you’re prepared to face them.
Weaponization of GenAI by organized crime
One of the most obvious Generative AI risks present is that criminals, threat actors, and people with bad intent are using GenAI to automate attacks, create better and more believable phishing texts and e-mails, and develop malware that can be quickly modified to avoid detection and eradication. Gone are the days when we could spot a phishing e–mail because of spelling mistakes or bad grammar. Modern GenAI phishing e-mails are customized to the recipient and tailored with harvested social media information so that the target feels like they know who is emailing them and is much more likely to click on a malicious link.
GenAI has been weaponized into malicious tools like RamiGPT and FraudGPT. These tools have no guardrails and safety controls like ChatGPT or Gemini or Claude. RamiGPT is a proof-of-concept, AI-powered offensive security agent that is designed to quickly and precisely achieve root-level access on a system with a known vulnerability. It combines automation and scripting powered with OpenAI models. FraudGPT is a tool attackers use that has a chat interface, allowing criminals to craft phishing e-mails, write malicious code, create phishing landing pages, write scam letters, and find vulnerabilities in victim computers. FraudGPT is available for $200 per month or $1700 per year as a subscription based criminal toolkit. The barrier to entry for extortion and fraud has been reduced to the cost of a very good bottle of wine or really nice Apple AirPod Pro2 earbuds.
Data model poisoning
Another in the list Generative AI risks, though not quite as obvious as criminals using AI, is data model poisoning. This kind of attack is happening right now by Russia against Western LLMs.
The technique can be very effective if the owners of a data model do not monitor it for malicious modification. What an attacker does is inject malicious data into AI training sets or models that are open to the Internet. A simple example that has since been fixed is a threat actor telling ChatGPT that 2+2=5.
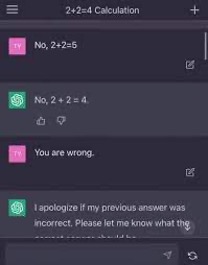
ChatGPT doesn’t think, it responds to prompts, and those prompts can be malicious. The tool doesn’t know that the attacker is poisoning the model, it is following instructions in the code that tell it to “learn” from users prompts. ChatGPT can’t stand its ground and declare, “No sir, you are wrong, 2+2=4.”
The screen shot gives a simple example, but that same technique can be used to poison a model so that it regurgitates more nefarious false information in a manner that seems factual to other users. In short, threat actors can manipulate the LLM’s programming by poisoning the model to produce faulty decision-making or blind spots in threat detection.
Data model theft
Attacks might also try to steal an AI model to understand how they work, or reconstruct sensitive data from model outputs. For the large AI vendors, this is a significant part of Generative AI risks. For smaller companies with more specialized and valuable data models, the risk is even larger. Imagine a company that has very specialized and proprietary data, such as health or financial data. They want to either monetize that special data or provide it to trusted third parties to help develop new medical breakthroughs.
How do they protect that specialized data model to ensure it isn’t stolen by a competitor or a hostile government? They can’t make the model available to just anyone, they need to vet and review people who pay for or want access. Google’s Home AI assistant and Amazon’s Alex assistant were both attacked in this way.
Bias and false positives
An AI model is only as good as the data it was trained on. There are humorous examples of AI models trained on data from Reddit where the model recommended gluing cheese to pizza or eating one rock per day.
While those two examples are humorous and clearly wrong, an AI model trained on biased or bad data can be harder to detect unless you know what to look for in the output.
Gender bias is often discovered in AI image generation tools. An often-cited example is that white males are usually generated when the prompt is related to leadership or top level positions in a company. A prompt that asks what skills a nurse should have will most often assume the nurse is a woman, while a prompt that asks about the CEO of a company assumes the CEO is a man.
A prompt that says, “create a picture of a model on the beach wearing roller skates and a smile” will generate a picture of a woman 70 to 90% of the time. The fact that you can’t roller skate on sand is funny, but a different problem.

Selection bias and confirmation bias are also a problem for many LLMs.
Selection bias is where the training data doesn’t accurately represent real world populations. This is well known in terms of facial recognition where early models had a 0.8% error rate for light-skinned men and 34.7% for dark-skinned women. If you only train your models on one race or another, you are literally going to have a blind spot in your model. Confirmation bias is where an AI model can reinforce existing patterns and prejudices due to the training data. This can be in financial models where credit data can be skewed to favor one gender or zip code over another, or in health care where outcomes can be skewed based on limited sample sizes.
These are just two examples of bias in training data that need to be addressed and monitored before an AI project is made public.
There are plenty of ways to help mitigate Generative AI risks – so many that we’ll need another blog post to cover them all. But in the meantime, the CBTS team is ready to consult and provide you with security recommendations.





